Regularization - L1 norm & L2 norm
Loss Function에 가중치들의 Norm을 더해서, Overfitting을 방지하고 Generalization 성능을 높이는 방법
학습이 진행됨에 따라 Loss 값이 점점 작아지면서
Outlier 등에 의해 가중치의 값이 과하게 커질 수 있는데,
Loss Function 업데이트 과정에서 가중치들의 Norm을 더해서
특정 노드와 노드 간의 가중치 값이 너무 커지는 것을 방지하는 효과
Pytorch에서는 "weight decay"로 구현돼있음 (L2-Norm)
<L2-Norm>
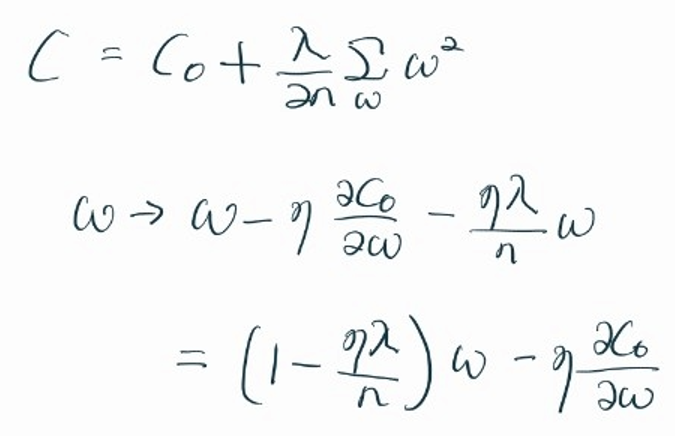
<L1-Norm>
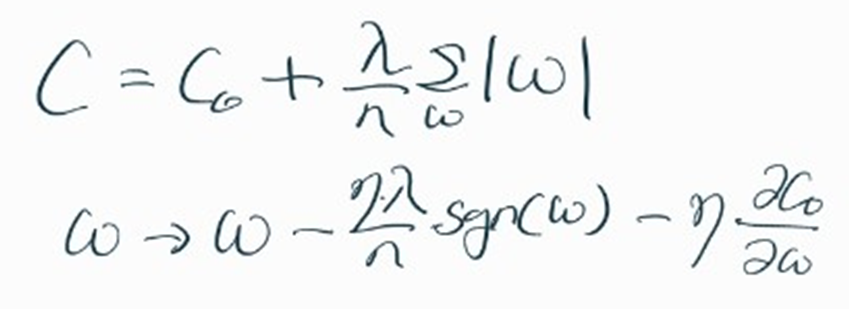
w 값에 상수항을 빼줌
▶ 애초에 작은 가중치는 0으로 수렴하게 된다.
▶ 몇 개의 중요한 가중치만 남게 된다.
▶ Sparse modeling에 적합
미분 불가능
<References>
https://m.blog.naver.com/laonple/220527647084
[Part Ⅲ. Neural Networks 최적화] 2. Regularization - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture P...
blog.naver.com
https://dp-story.tistory.com/4
2. Sparse modeling 소개
1. Sparse modeling이란? Linear equation \({\bf y = Ax}\)가 있다고 생각해보자, \(\bf y\)는 \(\bf m \times 1\)행렬이고, \(\bf A\)는 \(\bf m \times n\) 행렬, \(\bf x\)는 \(\bf n \times 1\)행렬이고, \(\bf m \ll n\) 이다. \(\bf y\)는
dp-story.tistory.com
Batch Normalization
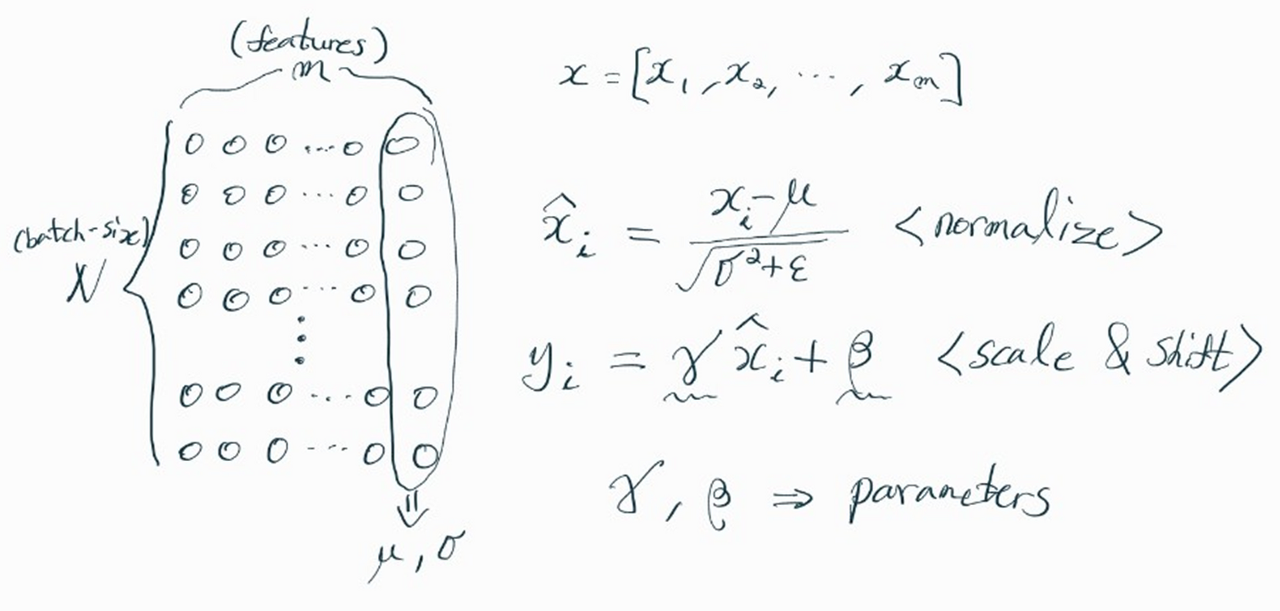
(Inference에서는, Training 과정에서 이동 평균 및 지수 평균 등을 활용해서 평균과 분산 구해놓음)
Layer가 깊을수록 노드를 거치면서 feature 값들의 분포와 스케일이 많이 달라진다.
→ weight 학습에 나쁜 영향을 미칠 수 있음.
→ 특정 weight만 크게 학습될 수 있음.
이런 문제들을 해결하기 위해,
○ Learning Rate 조절
○ Drop Out
○ Weight Initialize
등의 Regularization 기법 활용.
하지만 이런 기법들은 튜닝하기 어렵고, 학습 속도 저하를 발생시킬 수 있음.
☆ Batch Normalization로 학습 속도도 유지하면서, Regularization 효과를 얻을 수 있다.
(하지만 Sequential 데이터에는 적용하기 어려움)
(이를 위해, Layer Normalization 등의 기법 등장)
<References>
https://arxiv.org/pdf/1502.03167.pdf
https://gaussian37.github.io/dl-concept-batchnorm/
배치 정규화(Batch Normalization)
gaussian37's blog
gaussian37.github.io
https://eehoeskrap.tistory.com/430
[Deep Learning] Batch Normalization (배치 정규화)
사람은 역시 기본에 충실해야 하므로 ... 딥러닝의 기본중 기본인 배치 정규화(Batch Normalization)에 대해서 정리하고자 한다. 배치 정규화 (Batch Normalization) 란? 배치 정규화는 2015년 arXiv에 발표된 후
eehoeskrap.tistory.com
https://dive-into-ds.tistory.com/19
Whitening transformation
Whitening transformation(혹은 sphering transformation)은 random variable의 벡터(covariance matrix를 알고 있는)를 covariance matric가 identity matrix인 variable들로 변형하는 linear transformation이다. 즉, 모든 변수가 uncorrelated
dive-into-ds.tistory.com
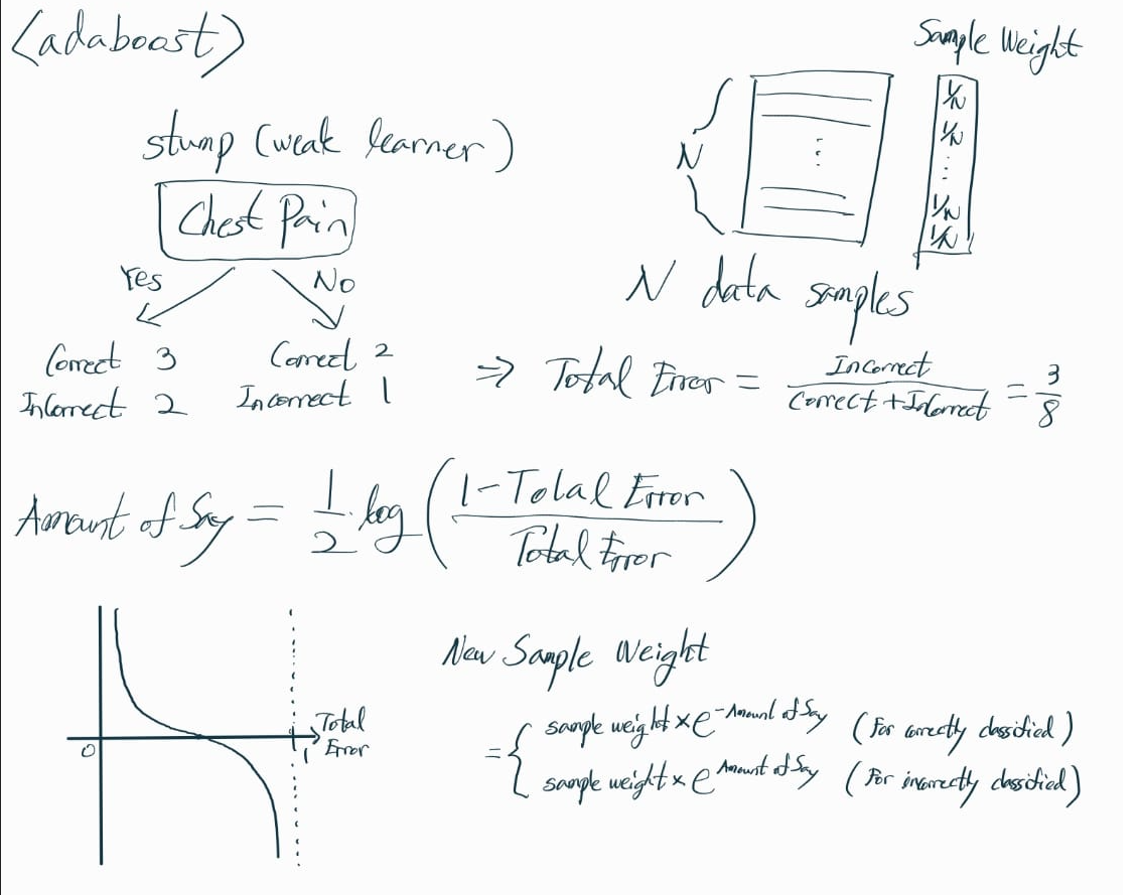
Adaboost
<Stump>
Tree와 다르게, decision 과정에 오직 하나의 variable만 사용한다. (Weak Learner)
<Adaboost>
이전 stump에서 틀렸던 data sample의 sample weight는 키워주고,
맞았던 data sample의 sample weight는 줄여준다.
다음 stump를 진행하기 위한 data samples 복원추출 과정에서,
sample weight가 높을수록 해당 data sample이 뽑힐 확률이 높아진다.
이렇게 새롭게 추출된 data samples를 바탕으로,
다음 stump 단계를 진행한다.
그리고 new data sample이 들어왔을 때,
전에 생성했던 weak learners의 amount of say의 합이 가장 큰 class로 decision making을 한다.
<References>
'Data Science' 카테고리의 다른 글
| Entropy & Surprise (0) | 2023.04.26 |
|---|---|
| Adaboost (0) | 2023.04.25 |
| Regularization - L1 norm & L2 norm (0) | 2023.04.24 |
| Batch Normalization (배치 정규화) (0) | 2023.04.24 |
| Maximum Likelihood Estimation (0) | 2022.12.19 |



