기존 Gradient Boosting 기법들의 문제점
1. Prediction Shift
Training data에 대한 Conditional distribution 과
Test data에 대한 Conditional distribution 이 서로 다르다.
(즉, 낮은 Generalization ability를 보인다.)
2. Target Leakage
Target Statistic (TS) 를 활용해서 Numerical Feature 를 Categorical Feature 로 바꿔줄 때,
Target인 y 값이 Feature value인 x 값을 정의하는데 이미 한 번 사용된다.
그러면 Conditional Shift 가 발생할 수 있다.
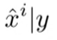
즉, Train과 Test set에서 y에 대한 x의 분포가 달라진다. (Conditional Shift)
Train data에서는 자기 자신의 y 값 (target 정보) 를 사용하지만,
Test dataset에서는 사용하지 않는다.
Ordered Target Statistics (= Ordered TS = Ordered Target Encoding)


Ordered TS : Target Leakage 문제를 방지하고, 위의 두 가지 properties를 최대한 만족하는 TS
Greedy TS (Target Statistics)
특정 Feature의 각 category 별 평균값 (mean) 으로 대체
Smoothing을 적용하는 이유는, 값이 0 또는 1에 가까운 경우가 있기 때문이다.
(Used to remove the negative effect of low-frequency noisy categories)

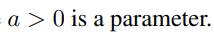

Training과 Test의 y 값 정보 활용 여부가 다르기 때문에,
위의 Property 1을 위반한다.
Holdout TS
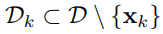
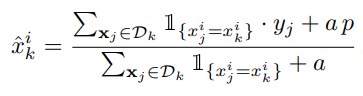
Current k-th training example을 제외하고 TS를 계산한다.
Dataset을 D0와 D1 두 개로 나눠서,

D0는 TS 계산에만 활용하고, D1을 통해 모델을 학습한다.
하지만, 이러면 Training을 위한 data가 줄어들기 때문에
위의 Property 2를 위반하게 된다.
Leave-one-out TS
자기 자신만을 제외해서 TS를 계산하고,
모든 data를 training에 활용하는 방식
하지만 이는 여전히 Target Leakage 가 발생하고,
위의 Property 1을 위반한다.
Ordered TS
먼저 Random Permutation을 적용해 dataset을 구성하고,
( sigma : Random Permutation 이 적용된 순열 )

data에 가상의 시간 (artificial time) 을 도입해서,
현재 시점의 k 번째 data 보다 이전 시점의 data들로 TS를 계산한다.
( 즉, sigma(j) < sigma(k) 를 만족하는 data examples )
Ordered Boosting
Prediction Shift 문제를 방지하기 위한 방법
F(t) 를 계산할 때, 1 ~ (t-1) 까지의 이전 tree 들에서 example x(k)를 계산에 사용하면 안된다.
( 안 그러면, Prediction Shift 발생할 수 있음 )
Ordered TS 와 마찬가지로, Random Permutation 적용



Oblivious Tree

CatBoost 에서는 Tree의 각 level에서의 split 기준이 모두 동일하다.
이렇게 함으로써 Overfitting 방지와 시간 단축의 효과가 있다.
논문에서 말하는 CatBoost의 장점
1. High cardinality categorical feature 를 다루는 데에 용이하다.
2. Oblivious Tree를 활용하기 때문에, Overfitting의 위험이 적고 속도가 기존 Boosting 기법 대비 빠르다.
3. Ordered TS와 Ordered Boosting 을 통해 높은 예측 성능을 보여준다.
◎ References
< paper, CatBoost: unbiased boosting with categorical features >
< 고려대학교 산업경영공학부 DSBA 연구실, 04-9: Ensemble Learning - CatBoost (앙상블 기법 - CatBoost) >
< 고려대학교 산업경영공학부 DSBA 연구실, [Paper Review]Catboost: Unbiased Boosting with Categorical Features >
< StatQuest, CatBoost Part 1: Ordered Target Encoding >
< StatQuest, CatBoost Part 2: Building and Using Trees >
< kicarussays 님 블로그, [논문리뷰/설명] CatBoost: unbiased boosting with categorical features >
'Data Science' 카테고리의 다른 글
| Covariance (0) | 2023.05.18 |
|---|---|
| SVM (Support Vector Machine) (0) | 2023.05.17 |
| XGBoost for classification (0) | 2023.05.06 |
| XGBoost for regression (0) | 2023.05.05 |
| Gradient Boosting (그래디언트 부스팅) for classification (0) | 2023.05.03 |



