Term-Frequency Inverse-Document-Frequency
TF (= Term Frequency)
◎ 특정 단어가 특정 문서에서 출현한 횟수
IDF (= Inverse Document Frequency)
◎ DF → 특정 단어가 등장한 문서 수
◎ IDF → DF의 역수
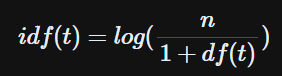
TF-IDF
◎ TF-IDF
= TF(word, document) * IDF(word)
→ 특정 문서에서 더 많이 등장하고, 등장한 문서 갯수가 적은 단어일수록 TF-IDF 값이 크다. (= 중요도가 더 높다.)
→ 따라서 ,"the"나 "a" 같이 거의 모든 문서에서 등장하는 단어들은 TF-IDF 값이 작아진다.
| Word \ Document | Doc 1 | Doc 2 | Doc 3 | Doc 4 | Doc 5 |
| Word 1 | 0 | 0.4 | 0.7 | 0.1 | 0 |
| Word 2 | 0.2 | 0.9 | 0.1 | 0.4 | 0 |
| Word 3 | 0.3 | 0.1 | 0.5 | 0.7 | 0.2 |
| Word 4 | 0 | 0 | 0.8 | 0 | 0 |
→ 행렬의 각 행과 열을, 각 단어 및 문서를 나타내는 벡터라고 생각할 수 있다.
→ 즉, 일종의 Word Embedding 방법으로 활용할 수 있다.
특징
◎ 장점
→ data-driven : 주어진 데이터를 기반으로 하기 때문에, 현재 데이터 및 Task에 특화됨 (Thesaurus 기반 방식과의 차이점)
◎ 단점
→ 단어 및 문서의 개수가 많아지면, 벡터의 차원이 너무 커진다. (Sparse Vector)
< References >
'Data Science' 카테고리의 다른 글
| GloVe (0) | 2023.10.07 |
|---|---|
| Word2Vec (0) | 2023.10.06 |
| 텍스트 데이터 전처리 (Text Preprocessing) (0) | 2023.10.02 |
| Central Limit Theorem (중심극한정리) (0) | 2023.07.16 |
| Mean Squared Error (MSE) (0) | 2023.06.16 |

