Word2Vec
◎ 희소 표현 (Sparse Representation)
→ 백터와 행렬의 값이 대부분 0으로 표현됨
ex) One-hot Encoding
◎ 분산 표현 (Distributed Representation)
→ 단어의 의미를 다차원 공간에 벡터화
→ 분포 가설을 가정함
→ 분포 가설 (distributional hypothesis) : 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다.
◎ Word Embedding
→ 분산 표현을 이용해, 단어 간 의미적 유사성을 벡터화 하는 작업
◎ Word2Vec
→ Word Embedding 방법 중 하나
→ CBOW와 Skip-gram 두 가지 방법이 있는데, 전반적으로 Skip-gram의 성능이 더 좋다고 알려져있다.
CBOW
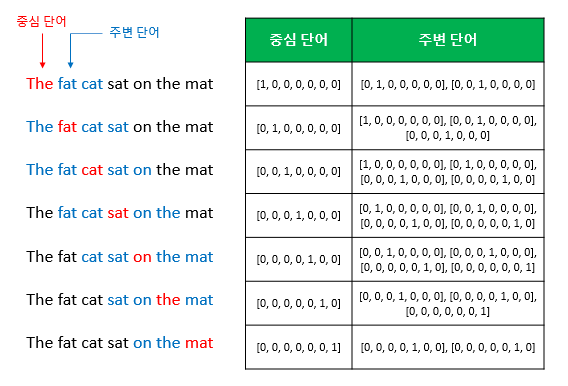


◎ 주변 단어들을 통해, 전체 단어 집합에서 하나의 중심 단어를 분류하는 multi-classification Task
→ 각 단어의 Embedding Vector를 학습
→ W 행렬의 k 번째 행이, 단어 사전에서 k 번째 단어의 Embedding Vector가 된다.
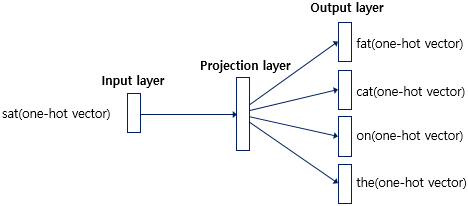
◎ 모델 구조
→ 은닉층(=Hidden Layer) 1개인 얇은 신경망이고, ReLU와 같은 활성화함수도 존재하지 않는다.
→ 주변 단어의 갯수만큼 은닉 벡터가 생성되므로, 모두 더해서 평균을 구한 다음 W' 행렬과 연산을 진행한다.
→ 손실함수 : 교차 엔트로피(=Cross Entropy)
Skip-gram
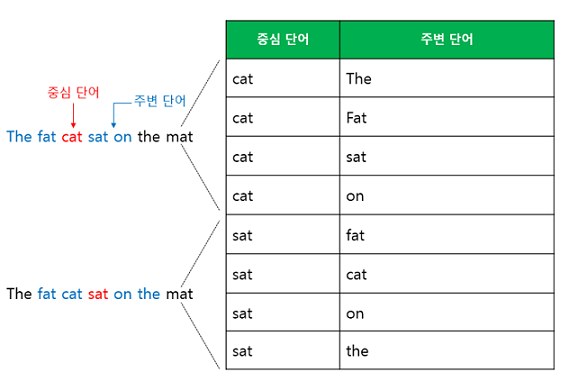
◎ 하나의 중심 단어를 통해 , 전체 단어 집합에서 주변 단어들을 각각 분류하는 multi-classification Task
→ 각 단어의 Embedding Vector를 학습
SGNS (Skip-Gram with Negative Sampling)
◎ 네거티브 샘플링(=Negative Sampling)
→ 주변 단어가 아닌(≒중심 단어와 유사도가 작다고 생각되는) 단어들을 무작위로 샘플링하는 방법


◎ 중심 단어 기준으로 주변 단어는 1, 그 외 단어들은 0으로 라벨링(labeling)한다.

◎ 두 개의 Embedding Table을 만들고 학습한다.
→ 왼쪽은 중심 단어의 embedding vector, 오른쪽은 그 외 단어들의 embedding vector들을 학습한다.
→ 단어들의 최종 embedding vector는 하나의 테이블만 쓰거나, 두 테이블을 조합해서 구할 수 있다.
◎ SGNS의 장점
→ 기존의 Skip-gram 방식은 one-hot vector로 분류하는 multi-classification Task
→ 단어 집합의 크기가 클수록 one-hot vector의 차원도 커지기 때문에, 학습하기 굉장히 무거운 모델이 될 수 있다.
→ SGNS는 Skip-gram을 0과 1을 분류하는 binary-classification Task로 변환시키기 때문에 훨씬 효율적이다.
< References >
※ arxiv, Efficient Estimation of Word Representations in Vector Space
'Data Science' 카테고리의 다른 글
| FastText (1) | 2023.10.08 |
|---|---|
| GloVe (0) | 2023.10.07 |
| TF-IDF (0) | 2023.10.02 |
| 텍스트 데이터 전처리 (Text Preprocessing) (0) | 2023.10.02 |
| Central Limit Theorem (중심극한정리) (0) | 2023.07.16 |
